Em Machine Learning temos diversos algoritmos que nos possibilitam agrupar dados em função de suas características e propriedades. Assim, Clusterização com Python: visualização de grupos é um post que auxilia a visualização de grupos ou clusterização com Python, sobretudo, deve ser assistida através de diversos algoritmos, dentre muitos, podemos citar:
- Density-based.
- Distribution-based.
- Centroid-based.
- Hierarchical-based.
- K-means clustering algorithm.
- DBSCAN clustering algorithm.
- Gaussian Mixture Model algorithm.
- BIRCH algorithm.
A clusterização (Clustering) com Python é uma tarefa de Machine Learning que é não-supervisionada. Quando se usa um algoritmo de clasterização, significa que passamos para o algoritmo diversos dados de entrada (input) e deixamos o algoritmo agrupar os dados de acordo com as propriedades desse algoritmo. Esses grupos são chamados de clusters; e esses clusters são grupos de dados que são similares entre si, e esta similaridades é baseada nas relações dos pontos vizinhos. A clusterização (Clustering) é usada frequentemente para descoberta de padrões, a chamada Pattern Recognition. A clusterização também pode ser usada no início de um trabalho de investigação e pesquisa para que se consiga alguns insights.
Quando usar os algoritmos de clusterização com Python
A Clusterização tanto pode ser o seu objetivo final num projeto de pesquisa como também pode ser só o início da pesquisa quando não se sabe muito sobre os dados. Clusterização pode ser usada para encontrarmos ou detectarmos anomalias e amostras que podem ser consideradas outliers. Ela encontrará e dividirá os grupos mostrando as fronteiras, assim, visualiza-se as amostras que pertencem ou não a determinada vizinhança.
Trabalhando nas etapas iniciais de um projeto de pesquisa, a clusterização pode ser determinante para indicar as variáveis mais importantes (features) para usarmos em Machine Learning.
Como escolher os grupos na clusterização
Como a Clusterização funciona de forma não supervisionada, os grupos são determinados pelos algoritmos. Na parametrização inicial escolhemos o número de grupos ou usamos técnicas que nos permitam escolher os clusters com base em critérios matemáticos. Assim, podemos segmentar os dados em quantos grupos acharmos necessário. Então, ultrapassada a fase de separação dos grupos, precisamos nos preocupar com a visualização destes grupos.
Além dos agrupamentos ou da clusterização
No mundo real, a clusterização usando Python pode ser aplicado em projetos acadêmicos, como nos tratabalhos de TCC (Trabalho de conclusão de Curso), dissertações de mestrado, teses de doutora, detecção de fraudes (empresas, bancos, seguros etc), livrarias (categorização de livros), segmentação de clientes e em outras atividades. Os diversos algoritmos existentes serão empregados de acordo com os tipos de dados.
Frequentemente, um aspecto importante a ser considerado, independente do algoritmo, é a visualização dos agrupamentos com Python. Entretanto, nem sempre se tem os grupos didaticamente separados, nesse caso, é fundamental o controle de como visualizar esses grupos. Por isso, além dos agrupamentos, as cores e o que elas representam assumem grande importância na tarefa de segmentação com Python.
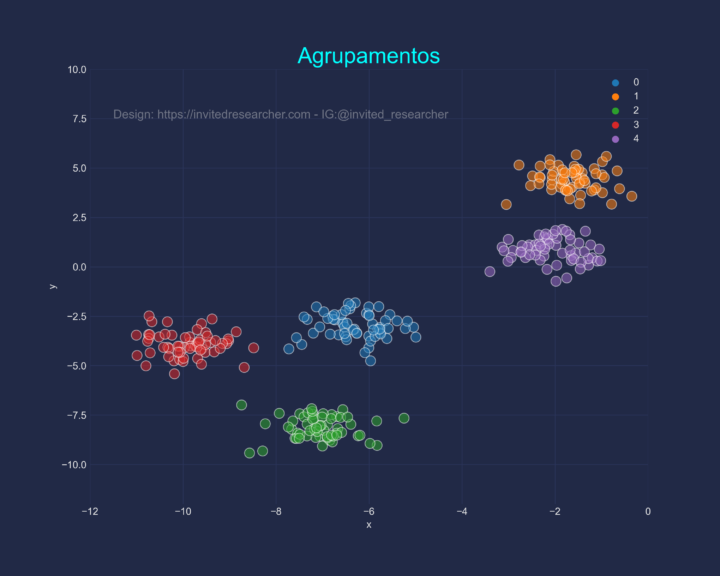
A Figura 1, abaixo mostra o resultado de uma clusterização usando Python e o algoritmo K-means (K-Means Clustering Algorithm ou K-Means Clustering). Acima de tudo, tão importante quando os grupos é a identificação desses grupos.

Nesse sentido, a Figura 2 mostra os grupos separados por cor e a legenda identifica cada grupo.

Entretanto, poderíamos considerar que os dados seriam representam melhor se tivéssemos dois grupos. Assim, poderíamos separar os grupos de acordo com a Figura 3.

Conclusão
Concluindo, tão importante quanto fazer a Clusterização com Python é encontrar a melhor representação para os agrupamentos. Finalmente, Saber escolher as cores de forma a representar os grupos é uma excelente tática.

Encontre aqui vagas e bolsas de Mestrado e Doutorado
Fundamentalmente, para você ter um direcionamento na sua Carreira Acadêmica é primordial saber e conhecer as oportunidades desse futuro que te espera. Sendo assim, preparei para você algumas oportunidades para ter acompanhamento, tanto para mestrado como para doutorado.
– Vagas e bolsas para Mestrado março de 2023
– Vagas e bolsas para Doutorado março de 2023
Quer turbinar teu trabalho acadêmico?
Já fiz Mestrado, Doutorado, Pós-Doutorado e participei de diversas bancas. Ajudo alunos de graduação, pós-graduação, mestrado, doutorado e profissionais a melhorar seus estudos aplicando Data Science.
Quer saber como posso te ajudar a melhorar teu trabalho acadêmico… Clique Aqui e não perca esta oportunidade!
Quer dominar Data Visualization.. Clique Aqui e eleve o nível dos teus gráficos!
Quer esclarecer alguma dúvida sobre apresentações, TCC, Mestrado, Doutorado ou Carreira Acadêmica?
Entre em contato pelo formulário abaixo e vamos fazer o planejamento do teu trabalho… não perca esta oportunidade!