
Segundo a definição mais usada, um mapa de calor ou como comumente é usado, heatmap, é uma técnica de visualização de dados que mostra a magnitude de um fenômeno em função da cor em duas dimensões. A variação na cor pode ser por matiz ou intensidade, tentando deixar o fenômeno visualmente mais intuitivo ao observador como o fenômeno está agrupado ou varia neste espaço bi-dimensional.

A definição do que é um heatmap já mostra como o seu uso pode ser amplo e de muita utilidade que vai desde a visualização de um fenômeno microscópico, passando pela visualização da área de atuação de um jogador dentro do campo até algo macro, como as áreas de queimadas em um continente ou as variações de temperatura do planeta.
Muitas são as maneiras de gerar um heatmap, entretanto um dos mais maiores problemas está em como será calculada a interpolação entre os pontos amostrados ou medidos, visto que o heatmap representa a variação do fenômeno ao longo de um espaço bidimensional, pontos conhecidos são usados para calcular-se os pontos onde não é conhecido o valor da variável de estudo. Assim, a qualidade do mapa de calor está ligada aos pontos utilizados como amostra, ao método de interpolação e, obviamente, ao resultado que se quer chegar. Torna-se essencial usar um interpolador que otimize os valores desconhecidos para que o resultado atinja os objetivos esperados, ou seja, uma superfície que represente de maneira fiel a variável de estudo ou o comportamento do fenômeno que se quer visualizar.
Python fornece funções que tornam o trabalho bem menos árduo, deixando o heatmap com a aparência que o codificador que.
Vamos a um exemplo, digamos que tenhamos uma variável, como por exemplo, a produção de determinado insumo, que foi medida ao longo do tempo, entre os anos de 2008 e 2019, mês a mês. Como a medição foi durante os meses desses 12 anos, gráficos de barras ou de linhas não dariam uma visão geral do que aconteceu nesse período de tempo. É aqui que o gráfico de calor entra em cena e mostra toda a sua utilidade.
Preparação dos dados
Os dados estão dispostos de forma tabelada onde é possível extrair-se uma matriz contendo os valores a serem tratados. A Figura um mostra um segmento da tabela com os dados.
Aqui, temos um parenteses, vamos usar o conceito de tabela dinâmica, em Python, pivot table, ou seja, queremos colocar a variável produção como uma função dos anos e meses. Como se tivéssemos um par ordenado (x,y) = z, nesse caso, (ano,mes) = prod. No caso da função que estamos usando (pois, existem duas no Python) ela não possui agregação que pode trabalhar com dado não numérico. O código em Python para fazer o pivot da tabela é constituído de apenas uma linha: df = df.pivot(“month”, “year”, “prod”)
A Figura 2 mostra como a tabela ficou depois do pivot.
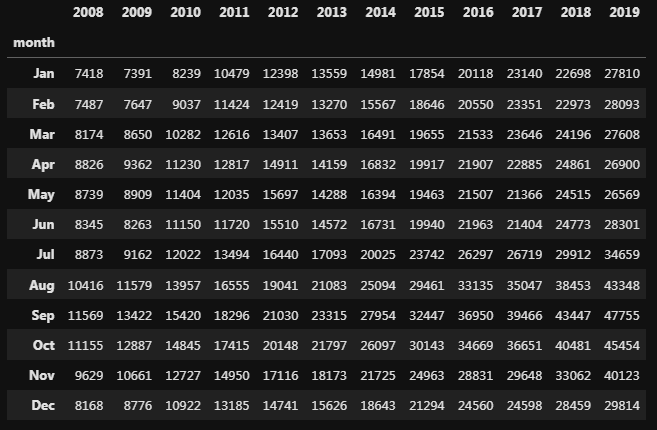
A Figura3 mostra um heatmap gerado com a biblioteca seaborn e a função heatmap. O mapa de calor não possui interpolação entre zonas e o que se vê são as cores assumidas para os valores que cada célula possui. Com o auxílio das cores a análise torna-se mais intuitiva contra a análise somente dos números. A escala de cores mostra as melhores e piores situações de desempenho da variável pesquisa. Os anos de 2008 e 2009 são os de pior desempenho sendo os meses de início e final de ano os piores. Em oposição observa-se que os anos de 2018 e 2019 são os de melhor desempenho, tendo os meses de agosto a outubro como os destaques. Na análise histórica mensal fica bem evidente que o mês de setembro é o melhor de mês. Os códigos para gerar os dois mapas de calor estão no final do post.

A Figura4 mostra o mesmo mapa de calor, entretanto usando a função imshow com um algoritmo de interpolação bilinear. As cores mostram-se mais suavizadas na transição entre células, mas mantendo-se fiel ao resultado obtido no heatmap anterior.

Conclusão
A utilização das duas metodologias para gerar os heatmaps mostram-se fieis ao que os dados representam. Com elas é possível visualizar os períodos onde acontecem os piores e melhores resultados. Com os mapas de calor os resultados são rapidamente visualizados.

